
محاسبات آماری در R : تحلیل اولیه داده ها (بخش نخست)
در ادامه بحث محاسبات آماری در زبان R و کار با دیتاست mtcars، در این بخش به صورت مشخص به تحلیل مقدماتی داده ها از طریق برخی از شاخص های آماری اولیه می پردازیم. پیش از بررسی هر یک از شاخص ها، می توان با استفاده از دستور summary اطلاعاتی کلی از 6 شاخص را برای هر یک از ستون ها (متغیرها) به صورت یک جا به دست آورد.
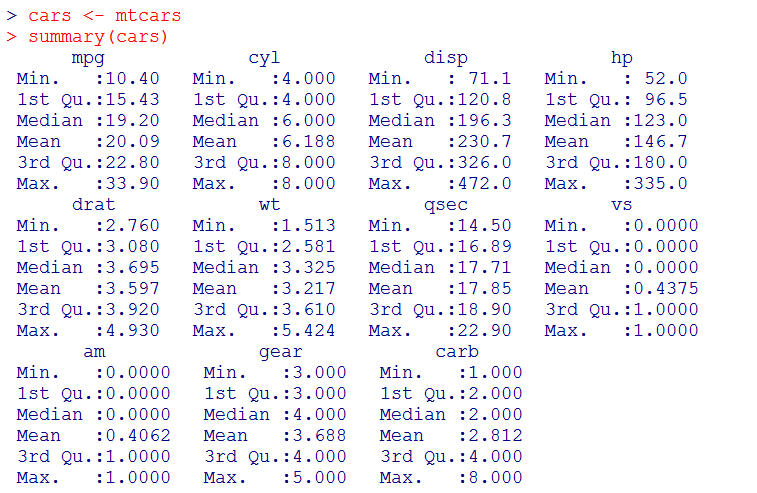
در این بخش و بخش های پیش رو هر یک از این مقادیر را بررسی می کنیم و خواهیم دید که چه اطلاعاتی را می توانیم از آن ها استنتاج کنیم.
مقادیر کمینه و بیشینه (Min and Max)
همانگونه که از عنوان این شاخص ها می توان متوجه شد، این توابع ریاضی اولیه در R به ترتیب کمترین و بیشترین مقدار موجود برای یک متغیر (ستون) را به عنوان خروجی در اختیار ما قرار می دهد. به عنوان مثال، برای متغیر mpg می توانیم این مقادیر را به صورت زیر بررسی کنیم.
min(cars$mpg)
# [1] 10.4
max(cars$mpg)
# [1] 33.9
این نتایج به ما می گوید که در میان 32 خودروی موجود در دیتاست، کمترین میزان مصرف سوخت در هر مایل برابر با 10.4 گالن و بیشترین مقدار برابر با 33.9 گالن می باشد. حالا بیاید یک گام جلوتر برویم و ببینیم که این مقادیر مربوط به کدام یک از خودروها هستند. از میان راه های مختلفی که برای دستیابی به این هدف وجود دارد، این روش را پیش می گیریم که ابتدا اندیس مربوط به مقادیر کمینه و بیشینه را پیدا می کنیم و سپس از آن برای دسترسی به اطلاعات آن سطر استفاده می کنیم.
which.min(cars$mpg)
# [1] 15
which.max(cars$mpg)
# [1] 20
cars [15,]
mpg cyl disp hp drat wt qsec vs am gear carb
Cadillac Fleetwood 10.4 8 472 205 2.93 5.25 17.98 0 0 3 4
cars [20,]
mpg cyl disp hp drat wt qsec vs am gear carb
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.9 1 1 4 1
روش دیگر برای انجام عملیات بالا و البته به صورت خلاصه تر و بدون نیاز به مواجهه با اطلاعات اضافی به صورت زیر می باشد.
rownames(cars)[which.min(cars$mpg)]
rownames(cars)[which.max(cars$mpg)]
نکته : مساله مهم درباره استفاده از توابع min و max محدودیت آن ها در مواردی است که مقادیر NA در داده ها وجود دارند. همانطور که در مثال های زیر مشاهده می کنید، در صورت وجود چنین مقادیری در میان داده ها، آن ها به عنوان کمینه و بیشینه انتخاب می شوند.
vec <- c (13, 189, NA, 90)
print(paste("min is", min(vec), "and max is", max(vec)))
# [1] "min is NA and max is NA"
برای رفع این مشکل باید مقدار یک پارامتر اختیاری را که موارد NA را از محاسبات حذف می کند از مقدار پیش فرض به TRUE تغییر دهیم.
min(vec, na.rm = TRUE)
# [1] 13
max(vec, na.rm = TRUE)
# [1] 189
علاوه بر یافتن مقادیر کمینه و بیشینه برای یک ستون (متغیر) مشخص، امکان بررسی چنین مقادیری برای تمامی ستون ها به صورت همزمان هم وجود دارد. برای انجام چنین عملیاتی از تابع sapply استفاده می کنیم. برای معرفی کاربردها این تابع و نسخه پیچیده تر آن (lapply) بخش مجزایی را درنظر خواهیم گرفت ولی به عنوان یک توضیح کوتاه توجه داشته باشید که این تابع یک دیتافریم، لیست و یا بردار را به همراه یک تابع به عنوان ورودی می گیرد و آن تابع را بر روی داده ها اعمال می کند و نتایج را در قالب یک ساختمان داده ساده سازی شده (بردار یا ماتریس) ارائه می کند.
اگرچه ممکن است درمورد دیتاست mtcars این مورد چندان ارزشمند به نظر نیاید ولی در سناریوهایی که نیاز به بررسی مقادیر بیشینه و کمینه برای چند ستون به صورت همزمان وجود دارد، می توانیم به صورت زیر عمل کنیم.
max(c(mtcars$mpg, mtcars$cyl, mtcars$hp))
# [1] 335
min(c(mtcars$mpg, mtcars$qsec, mtcars$gear))
# [1] 3
مشابه بررسی پیشین، یافتن مقادیر کمینه و بیشینه در یک سطر برای این دیتاست چندان بامعنی به نظر نمی آید ولی در مواردی متعددی می تواند بسیار کاربردی باشد. این عملیات را هم می توان به شکل زیر انجام داد. توجه داشته باشید که برای اشاره به هر سطر، از اندیس مربوط به آن استفاده می کنیم.
min(cars[8,])
# [1] 0
max(cars[8,])
# [1] 146.7

دیدگاه ها
ارسال دیدگاه